构建高可用大数据分析系统 从架构设计到服务实现
在数据驱动决策的时代,大数据分析系统已成为企业运营的神经中枢。其高可用性不仅关乎业务连续性,更直接影响决策质量与用户体验。本文将系统阐述大数据分析系统高可用架构的设计理念与实现路径,旨在为构建稳健、弹性的大数据服务提供参考。
一、高可用架构的核心设计原则
- 冗余与容错:通过多副本机制(如HDFS数据块副本、Kafka分区副本)确保单点故障不影响整体服务,实现数据与计算资源的冗余备份。
- 负载均衡与弹性伸缩:采用自动化负载均衡策略(如YARN资源调度、Kubernetes容器编排),结合动态扩缩容机制应对流量峰值,避免资源瓶颈。
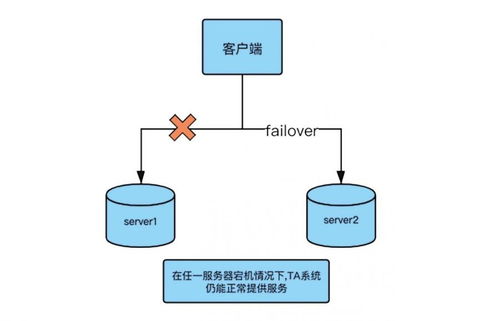
- 故障隔离与快速恢复:通过微服务化部署、多可用区(AZ)分布实现故障隔离,并设计监控告警与自动化恢复流程(如健康检查、服务自愈),将平均恢复时间(MTTR)最小化。
- 数据一致性与最终一致性:根据业务场景权衡强一致性(如金融交易)与最终一致性(如日志分析),采用分布式一致性协议(如ZooKeeper、Raft)或异步复制机制保障数据可靠性。
二、分层架构设计与关键技术选型
- 数据存储层:
- 分布式文件系统(如HDFS、S3)采用多副本存储与纠删码技术,提升数据持久性。
- 分布式数据库(如HBase、Cassandra)通过主从复制或分布式共识协议保证读写高可用。
- 计算处理层:
- 批处理框架(如Spark)结合动态资源分配与检查点(Checkpoint)机制,避免作业中断。
- 流处理引擎(如Flink)利用精确一次(Exactly-Once)语义与状态后端容错,保障实时计算连续性。
- 服务调度层:
- 资源管理器(如YARN、K8s)通过主备模式(Active-Standby)与故障自动切换,确保调度服务不中断。
- 消息队列(如Kafka)依赖分区副本与ISR机制,实现消息零丢失与高吞吐。
- 监控治理层:
- 集成全景监控系统(如Prometheus+Grafana)实时追踪集群健康度,设置多级告警阈值。
- 借助混沌工程工具(如ChaosBlade)定期模拟故障,验证系统容错能力。
三、高可用大数据服务的实现路径
- 多活部署与异地容灾:
- 在同城多机房或跨地域部署集群,通过数据同步工具(如DistCp、Brooklin)实现数据双活,结合DNS/GSLB进行流量调度,确保地域级故障时服务无缝切换。
- 自动化运维与DevOps实践:
- 利用IaC(基础设施即代码)工具(如Terraform)统一编排资源,结合CI/CD流水线实现部署标准化与版本回滚能力。
- 构建智能运维(AIOps)平台,通过机器学习预测资源瓶颈并自动优化配置。
- 成本与性能的平衡:
- 采用混合云或云原生架构,按需使用竞价实例与预留实例,在保障可用性的同时控制成本。
- 通过数据分层存储(热/温/冷数据)与计算资源池化,提升资源利用率。
四、挑战与演进方向
- 复杂依赖下的故障传导控制:需通过服务网格(如Istio)实现细粒度流量治理,避免链式雪崩。
- 云原生与Serverless融合:未来高可用架构将更依赖容器化、无服务器计算(如AWS Glue、Google Dataflow)的弹性优势,实现“零运维”容错。
- 智能弹性与自愈能力:结合AI算法实现故障预测与主动规避,推动系统从“高可用”向“永远在线”演进。
大数据分析系统的高可用架构是一个持续演进的系统工程,需在技术选型、流程规范与组织协同上形成闭环。唯有将冗余设计、自动化运维与业务连续性规划深度融合,才能打造出既稳健又敏捷的大数据服务,真正释放数据价值。
如若转载,请注明出处:http://www.banyiw.com/product/5.html
更新时间:2026-06-18 01:31:48